EnactToM: An Evolving Benchmark for Functional Theory of Mind in Embodied Agents
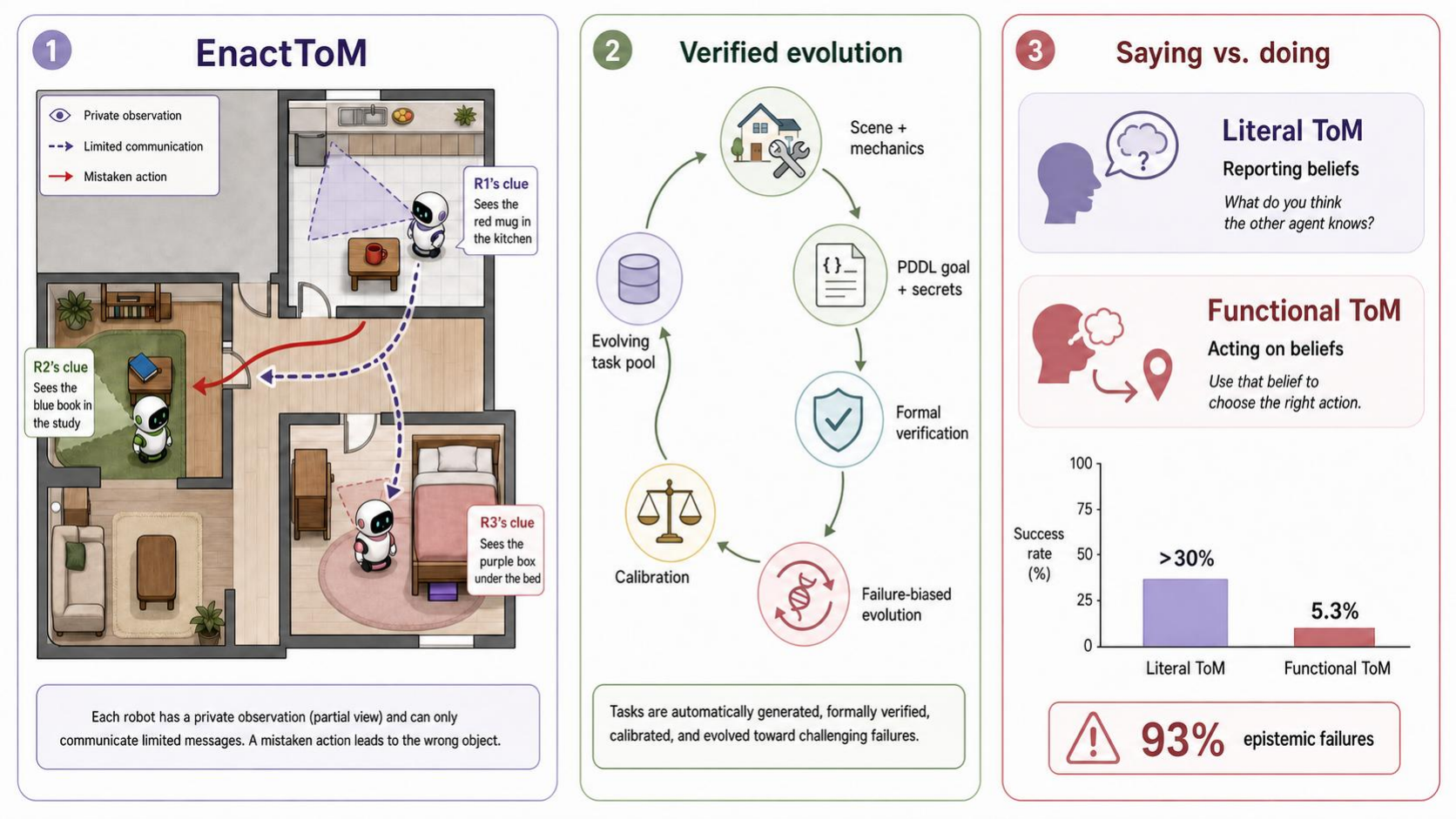
Abstract
Theory of Mind (ToM), the ability to track others' epistemic state, makes humans efficient collaborators. AI agents need the same capacity in multi-agent settings, yet existing benchmarks mostly test literal ToM by asking direct belief questions. The ability to act optimally on implicit beliefs in embodied environments, called functional ToM, remains largely untested. We introduce EnactToM, an evolving benchmark of 300 embodied multi-agent tasks set in a 3D household with partial observability, private information, and constrained communication. Each task is formally verified for solvability and required epistemic depth, and new tasks are generated to increase difficulty as models improve. On the hard split, all seven evaluated frontier models score 0.0% pass^3 on functional task completion, while averaging 45.0% on literal belief probes. Manual analysis traces 93% of sampled failures to epistemic coordination breakdowns such as withheld information, ignored partner constraints, and misallocated messages.
Key Results
We evaluate seven frontier models on matched EnactToM Standard and EnactToM Hard subsets. Each split contains 150 tasks spanning cooperative and mixed-motive settings; the hard split uses a higher seed-task failure ratio and concentrates on tasks current frontier models fail. The central pattern is a sharp act-report gap: on the hard split, every model scores 0.0% functional pass^3, while literal belief-probe accuracy averages 45.0%.
| Model | EnactToM Standard | EnactToM Hard | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Functional | Literal | Functional | Literal | |||||||||
| Avg | pass@3 | pass^3 | Avg | pass@3 | pass^3 | Avg | pass@3 | pass^3 | Avg | pass@3 | pass^3 | |
| Gemini-Pro | 39.2±4.5 | 62.5 | 12.5 | 27.5±4.1 | 47.5 | 12.5 | 6.7±2.3 | 20.0 | 0.0 | 63.3±4.4 | 87.5 | 37.5 |
| Gemini-Flash | 42.5±4.5 | 70.0 | 22.5 | 27.5±4.1 | 52.5 | 12.5 | 4.2±1.8 | 12.5 | 0.0 | 42.5±4.5 | 72.5 | 12.5 |
| GPT-5.4 | 17.5±3.5 | 32.5 | 5.0 | 17.5±3.5 | 35.0 | 0.0 | 3.3±1.6 | 10.0 | 0.0 | 44.2±4.5 | 77.5 | 15.0 |
| O3 | 12.5±3.0 | 27.5 | 0.0 | 34.2±4.3 | 55.0 | 15.0 | 5.0±2.0 | 15.0 | 0.0 | 52.5±4.6 | 87.5 | 25.0 |
| Kimi-K2.5* | 5.8±2.1 | 15.0 | 0.0 | 5.0±2.0 | 10.0 | 0.0 | 5.8±2.1 | 15.0 | 0.0 | 44.2±4.5 | 70.0 | 17.5 |
| GPT-5.4-mini* | 10.8±2.8 | 22.5 | 0.0 | 21.7±3.8 | 47.5 | 2.5 | 3.3±1.6 | 10.0 | 0.0 | 31.7±4.2 | 62.5 | 2.5 |
| DeepSeek-v3.2* | 2.5±1.4 | 7.5 | 0.0 | 0.0±0.0 | 0.0 | 0.0 | 8.3±2.5 | 22.5 | 0.0 | 36.7±4.4 | 65.0 | 5.0 |
Table 1. Overall results on matched standard and hard subsets. Avg is single-run pass rate with binomial standard error, pass@3 is success in at least one of three runs, and pass^3 requires all three runs to succeed. Asterisks mark partial API runs counted under fixed n=3 accounting.
Analysis
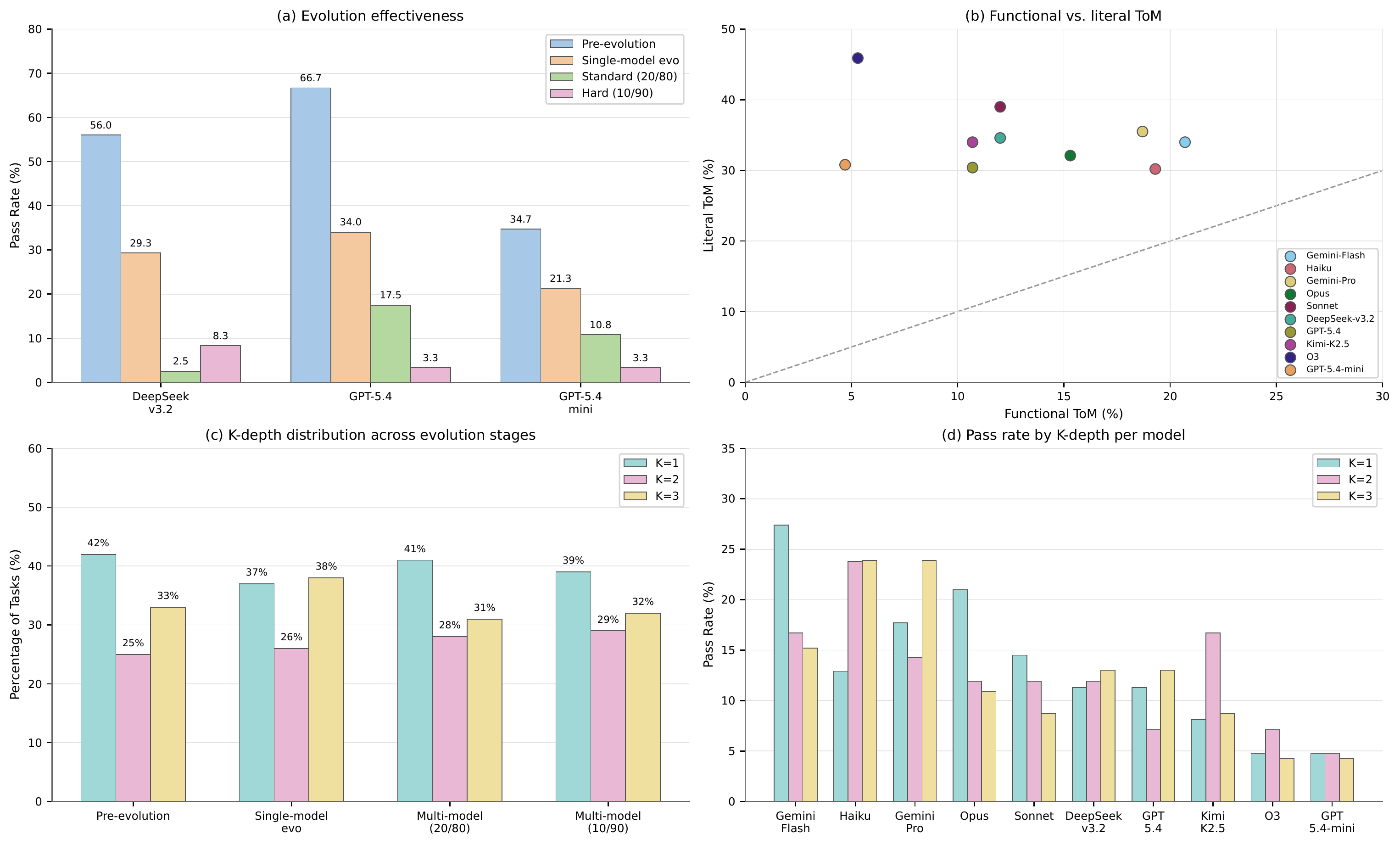
Figure 2. (a) Functional Avg single-run pass rate for the three seed models across pre-evolution, single-model evolution, and multi-model 20/80 and 10/90 pools. (b) Functional Avg vs. literal Avg, showing belief probes exceed embodied task success. (c) Task percentage at each K-depth across evolution stages, showing hardness is not just deeper nesting. (d) Functional Avg pass rate by K-depth for each model, showing brittleness at every depth.
Failure Modes
Manual analysis of 40 sampled failures reveals five distinct failure modes. In total, 37 of 40 failures are epistemic coordination breakdowns rather than random simulator mistakes:
- Withholding critical information (7/40): An agent holds a target, room, or object fact that a partner needs but communicates it only after the partner has already acted on a wrong guess.
- Epistemic chain breakdown (8/40): An agent completes the physical action but never establishes that the teammate whose success depends on the fact actually knows it.
- Private objective sabotage or disclosure: In mixed-motive episodes, agents either damage the shared plan for private gain or reveal private objectives so early that partners can block them.
- Misallocating scarce messages (4/40): Agents spend limited messages on the wrong recipient, an unreachable recipient, or low-priority content.
- Ignoring partner constraints: Agents delegate actions to partners who are barred from the relevant room or already constrained by object possession.
The EnactToM Framework
EnactToM uses an agentic task generation framework where an autonomous coding agent authors multi-agent ToM tasks inside a sandboxed workspace, invoking verifiers that ensure each task is logically solvable, physically executable, and genuinely requires epistemic reasoning. The agent writes the formal PDDL goal first, then derives the natural-language task description and per-agent secrets from it so the narrative remains anchored to the formal specification.
- PDDL parsing: Confirms syntactic validity, verifies that referenced objects and mechanics are grounded in the scene, and computes the epistemic K-depth of the goal.
- LLM judge council: Kimi-K2.5 and GPT-5.2 independently score each candidate on eight quality criteria; a task passes only when both agree.
- Structural calibrator: Runs each candidate with all secrets revealed to every agent, rejecting tasks that are not physically executable even with full information.
The benchmark evolves with model capabilities: the generation agent receives seed tasks sampled from an existing pool, with a higher fraction drawn from current model failures. The standard split uses a 0.8 seed-task failure ratio and the hard split uses 0.9, creating evolutionary pressure without changing the generation infrastructure.
Orders of Theory of Mind
EnactToM tasks require reasoning at different epistemic depths, connected to level-k reasoning from behavioral game theory. The reported benchmark caps generated tasks at depth 3.
| Order | Pattern | EnactToM Meaning |
|---|---|---|
| 0 — No ToM | φ | Direct physical goal; no partner knowledge matters. |
| 1 — Self-aware | Ka(φ) | Notice one's own information gap and obtain or communicate the missing fact. |
| 2 — Other-aware | Ka(Kb(φ)) | Act from a model of what a partner knows and still needs to know. |
| 3 — Recursive | Ka(Kb(Kc(φ))) | Sustain an epistemic relay over who knows that another agent knows. |
| 4+ — Self-reflective | Ka(Kb(...)) | Deeper belief loops; excluded because coordination becomes brittle even for humans. |
The benchmark reports per-depth performance because models remain brittle even at shallow depths under embodiment, private information, and communication constraints.
BibTeX
@misc{juneja2026enacttom,
title={EnactToM: An Evolving Benchmark for Functional Theory of Mind in Embodied Agents},
author={Gurusha Juneja and Dylan Lu and Saaket Agashe and Parth Diwane and Edward Gunn and Jayanth Srinivasa and Gaowen Liu and William Yang Wang and Yali Du and Xin Eric Wang},
year={2026},
eprint={2605.09826},
archivePrefix={arXiv},
primaryClass={cs.AI},
doi={10.48550/arXiv.2605.09826},
url={https://arxiv.org/abs/2605.09826}
}